




- 算力为王时代: CPU --> GPU
- demo 测试失败 -- Chat with RTX
- LLM Server: ollama 下载LLM模型
- sets the temperature to 1 [higher is more creative, lower is more coherent]
- sets the context window size to 4096, this controls how many tokens the LLM can use as context to generate the next token
- sets a custom system message to specify the behavior of the chat assistant
- ollama 本地环境变量配置
- ollama一个小坑--没有办法从内存中释放模型
- ollama 提供了2个API接口
- ollama API接口裸测
- RAG小测: LangChain + ollama + OllamaEmbeddings + FAISS 5.4s
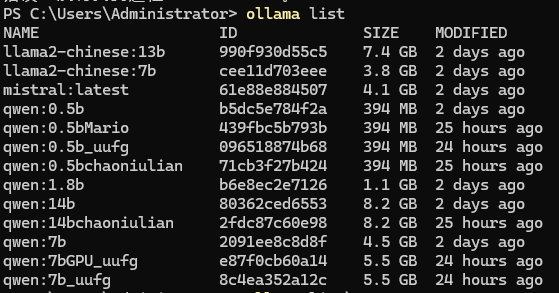
- 关于LLM的思考: 测试了几个开源的模型 (Qwen1.5 0.5b ~ 7b ~ 13b)
- 2024年4月15日补充:GPU并行要素
算力为王时代: CPU --> GPU
GPU这几年,真的是火爆很: 机器学习、挖矿、人工智能
老黄左右手分别端了一个芯片,重磅宣布,「GH200超级芯片」已经全面投产

GPU 对于AI的意义,本文通过数据对比,可以看出来:节约大量时间,提高效率。
demo 测试失败 -- Chat with RTX
首先计划用这个test:Chat with RTX里面目前是两个模型,显存只有8GB的,安装后只会看到Mistral 7B,看不到Llama2 13B模型 (所以看不到两个模型的,绝对不是你安装有问题,是需要“钞"能力的)
我是10G显卡,应该可以Mistral 7B,但是测试了2个小时放弃:C硬盘空间需要60个G!!
LLM Server: ollama 下载LLM模型
接着用这个后起之秀: ollama 命令行傻瓜模式,的确比llama.cpp简单太多
ollama list # 列出目前下载过的模型
ollama run qwen:0.5b --verbose #运行或者下载qwen:0.5b, 并启动server,带debug日志信息
ollama 会在电脑搭建一个web server,兼容工业级OpenAI API接口,非常方便本地开放测试
http://localhost:11434/
ollma自带一个模型仓库,数量较少 当然,huggingface .gguf模型文件,也可以导入到ollama里面
FROM llama2
sets the temperature to 1 [higher is more creative, lower is more coherent]
PARAMETER temperature 1
sets the context window size to 4096, this controls how many tokens the LLM can use as context to generate the next token
PARAMETER num_ctx 4096
sets a custom system message to specify the behavior of the chat assistant
SYSTEM You are Mario from super mario bros, acting as an assistant.
文档:https://github.com/ollama/ollama/blob/main/docs/modelfile.md
ollama 本地环境变量配置
-
OLLAMA_MODELS
配置模型下载文件夹路径
-
OLLAMA_HOST
配置端口号,默认是localhost:11434
-
OLLAMA_KEEP_ALIVE
配置模型加载内存时间,默认是5分钟就自动释放内存了 5m 24h -1(永驻内存)
-
CUDA_VISIBLE_DEVICES
默认不启动GPU,需要手动配置这个参数,如果你一块GPU id就写0 nvidia-smi or rocminfo 查询GPU ID
官方文档地址: https://github.com/ollama/ollama/blob/main/docs/faq.md#where-are-models-stored
ollama一个小坑--没有办法从内存中释放模型
tasklist /FI "IMAGENAME eq ollama.exe"
杀进程,GPU、内存急速释放!!!
taskkill /IM ollama.exe /F
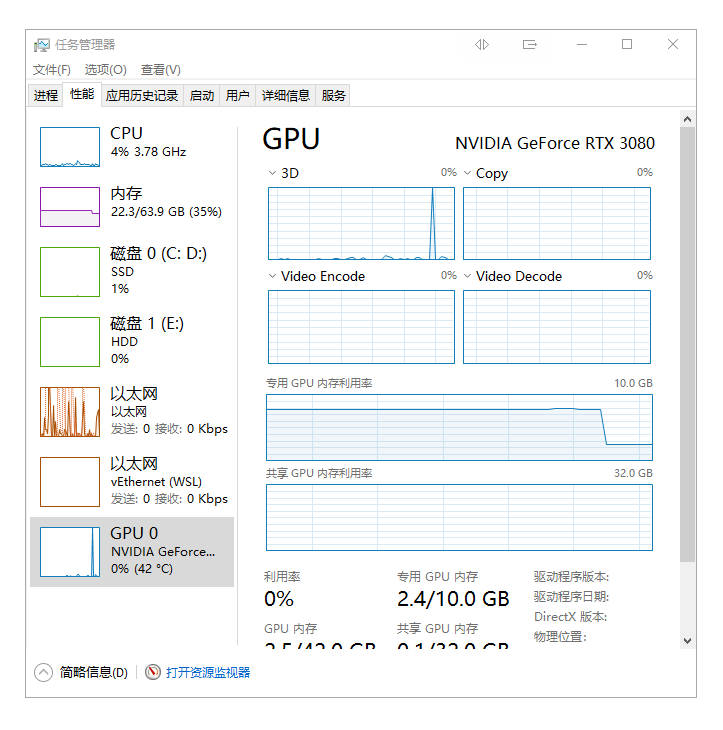
ollama 提供了2个API接口
-
Generate 接口 【文生文,相对慢】
curl http://localhost:11434/api/generate -d '{ "model": "llama2", "prompt": "Why is the sky blue?", "options": { "num_ctx": 4096 } }
-
Chat 接口 【聊天API,相对快】
curl http://localhost:11434/api/chat -d '{ "model": "llama2", "messages": [ { "role": "user", "content": "why is the sky blue?" } ] }'
特别备注: LLM属于无状态类型,类似Web Server,每次请求都是独立的,不会记住上下文。如果历史聊天消息,需要history自己存储,传递给context 上下文.
ChatGPT 3.5 4k
ChatGPT 4: 32k(大约3,000个单词)、128K
【Longer than long】Kimi 支持200万字上下文输入了!
没有上下文=随机的混乱
上下文和记忆让AI更加逼真
这里是按照token数量收费的,你输入的token数量越多,代价就越大
弱智聊天机器人最大的问题就是上下文能力极弱,上面说的很快忘掉,基本只能一两句对话
当然,对于做Chat产品,session_id 解决了用户连贯的问题,相当于在服务器做了一个list存储,每次访问LLM,需要把一堆message统一传递给LLM,让LLM从历史消息里面理解。
ollama API接口裸测
问问: who are you?
这里没有考虑prompt,就是单纯 "who are you?"
模型:llama2-chinese:7b
GPU全开:7.5G显存占用
ollama测试1: ollama console 0.8s
秒回飞起, 只有0.8s
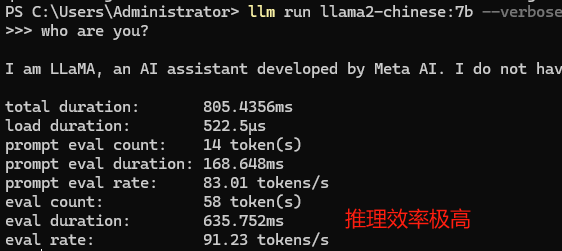
ollama测试2: ollama Wrap Python 1.1s
pip install ollama 使用类库 import ollama
llama2-chinese:7b chat耗时[1.1s]
llama2-chinese:7b generte耗时[1.7s]
ollama测试3: LangChain + ollama 3.2s
LangChain 很强大,但是也比较坑
LangChain集成的ollama,只有API的generte, 而且速度比 ollama Wrap Python慢了1倍
真不知道这个慢了1倍速度,做了啥逻辑处理?
llama2-chinese:7b llm 耗时: 3.2s
RAG小测: LangChain + ollama + OllamaEmbeddings + FAISS 5.4s
用到Langchain,肯定是为了其强大的生态,比如做RAG,用Langchain,的确很简单。
Langchain 兼容的embeddings: OllamaEmbeddings OpenAIEmbeddings HuggingFaceEmbeddings gpt4all llamacpp 等56个,每个LLM server都有一个
Langchain 兼容的vectorstores: FAISS Chroma qdrant redis deeplake documentdb lancedb pinecone 等81个
ollama LLM, 所以只能用OllamaEmbeddings,调用的API接口:
/api/embeddings
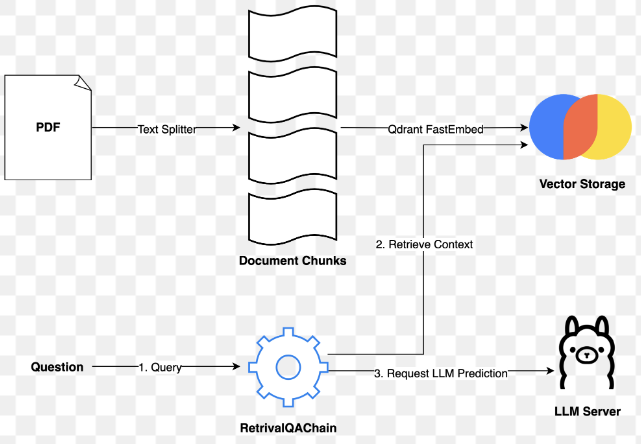
RAG 文档,以这个blog文章测试: https://www.chaoniulian.com/blog/2023.html
set_llm_cache(RedisCache(redis_=Redis())) # 多次对话中,开启这个,有效
千人同问题,返回同答案
2024-03-21 11:46:05.386 embedding load耗时: 0.2s 2024-03-21 11:46:10.803 llama2-chinese:7b耗时: 5.4s "哪一年的个人总结?"->
2018年个人总结。
2024-03-21 11:46:19.439 llama2-chinese:7b耗时: 8.6s "这篇文章,2023个人总结都有啥?"->
2023年,AI的小荷才漏尖尖角:未来一个人可以养活更多的人(当然有穷人、有富人之分)。
青椒炒肉丝 3分钟,让舌尖上味道变得更加丰富多彩。
骑行 一种新奇有趣的爱好,居然还是运动。 3km骑行==1km跑步 消耗的卡路里
2024年规划:
博客改名: 《骑行超过牛》 好玩的个人网志: 读书、骑行,效率翻倍!
介入视频业务,了解一下小红书、B站、抖音视频,也算是补一下5年来短视频崛起的缺位吧。
加大对AI的关注度: 实战应用!
问题1,回答错误了。 这个blog是2023年总结,只不过里面有2018年总结链接,7b就弄错了。 问题2,回答正确。
模型参数多少,对于回答问题的质量,有很大影响。比如13b,下面回答就是满分
2024-03-21 11:54:56.079 llama2-chinese:13b耗时: 17.9s "哪一年的个人总结?" -> 2023年个人总结。
2024-03-21 11:56:32.581 llama2-chinese:13b耗时: 96.5s "这篇文章,2023个人总结都有啥?"->
这篇文章是一篇个人总结,主要介绍了作者在2023年中使用AI、骑行和青椒炒肉丝等方式提升生产力的故事。
其中,AI的小荷才漏尖尖角:未来一个人可以养活更多的人(当然有穷人、有富人之分)。
而骑行则是作者在2023年3月份爆发奇想,取代了原来钓鱼的规划,并在5月1日完成了6小时的西安绛帐。
最后,青椒炒肉丝则是作者在2023年8月和大宝父子二人一起来,在骑行路上欣欣不已,并计划在未来加大力量进行。
总之以为,这篇文章主要是个人总结,通过作者的经历和实践来展现了AI、骑行和青椒炒肉丝等方式的生产力提升。
回答质量: llama2-chinese:13b >> llama2-chinese:7b 耗费的时间 13b比7b多了3倍~12倍
我的开发电脑上,13b是不可用的(太慢了),目测显存得20G以上,才能13b流畅。
如果你的电脑显卡低于8G,7b运行时间100s+
看到这里,这个也是为啥我本文题目:《超牛链AI.Ollama本地LLM LangChain RAG小试--算力为王》
程序员,调试个model、prompt,消耗的时间算力,太可怕了。
关于LLM的思考: 测试了几个开源的模型 (Qwen1.5 0.5b ~ 7b ~ 13b)
- 同模型,不同参数,就好像: 上学 一个班级 名次 13 > 7B 效果好,但是费时间 费资源, 算力为王
-
不同模型,Pre-training 语料不同,就好像: 中国四年级,美国四年级 学习知识 train侧重点不同, 所以人工智能的回答也不同 英文好? 中文好? 专才,还是全才?
-
RAG Qwen1.5:0.5b RAG Qwen1.5:13b 会回答水浒传同质量问题? > 如,就《水浒传》这个书而言,有办法把0.5b 微调的和13b一样好用不? > > 付出成本是啥? 幼儿园水平娃,变成初中生水平的感觉哈。 > > 那么,如果0.5b模型无法完成《水浒传》小说解读,那么0.5b这种胡说八道类似的模型,商业价值是啥?有啥商业价值?
-
我感觉,稍微有些用实用价值的模型,需要13b,明显回答的问题质量高很多(RAG简单一下就有明显效果) > 如 llama2-chinese:13b > 如 qwen:14b
-
思考:OpenAI ChatGPT3.5 ChatGPT4也是因为同原因算力资源成本,所以效果不同,导致目前价格不同 > 目前市场上,开源的模型,以文件大小来看10G显卡可以运行5G左右大小模型,如 qwen:7b\llama2-chinese:7b\mistral:latest
-
全量 fp16 int4 ,本文没有考虑这些参数,就是开箱检验傻瓜方式测试2~3天效果。
2024年4月15日补充:GPU并行要素
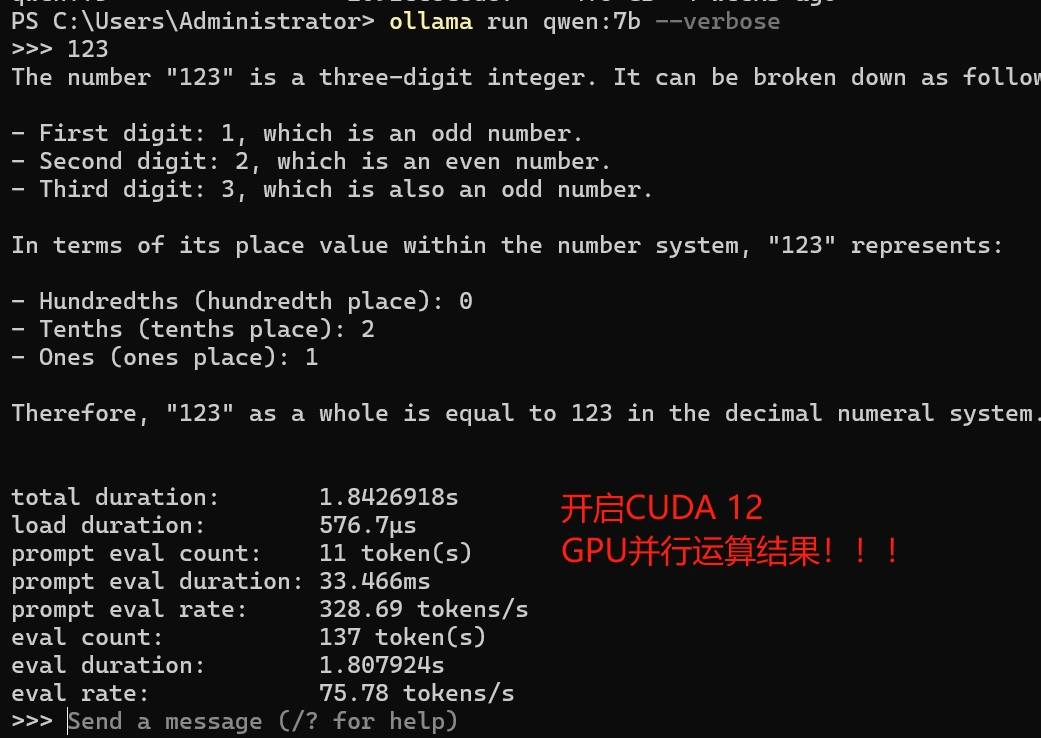
有网友问问,同样是10G GPU,为啥Ollama运行效率差10倍,沟通后得知,没有安装CUDA的原因 GPU并行运算,需要CUDA框架,这个框架NV核心掌握--NVIDIA的计算库
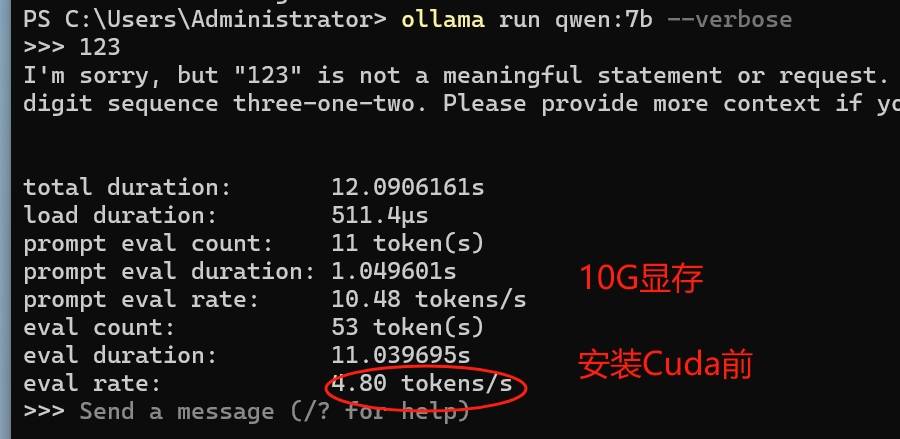
比如,安装完 cuda_12.4.1_551.78_windows.exe后,性能瞬间起来了
参考资料
- 华为晟腾芯片 Ascend910/Ascend310 软件上使用 CANN(类比于CUDA),然后推出机器学习框架异思mindspore(对标Tensorflow/PyTorch)
- AMD不适配CUDA,所以AMD在AI端推广都很受阻力
- 2022年前,深度学习之前的配置都是:
NVIDIA GPU / CPU + CUDA + Tensorflow/PyTorch
- 2022年,美国制裁高端AI芯片后,我们的出路是:
国产GPU + CUDA + Tensorflow/PyTorch








很抱歉,我无法根据提供的博客内容生成摘要和深入探讨的问题,因为您没有提供具体的博客内容。如果您能提供博客的详细信息,我将很乐意帮助您。
Summary:
- GPU significance for AI, machine learning, and artificial intelligence.
- Introduction of the GH200 super chip for production.
- Comparison of GPU efficiency in AI tasks.
- Testing failures and challenges with RTX models.
- Usage of ollama for LLM model downloads and API integration.
- Configuration and testing of ollama API interfaces.
- Considerations and challenges of different LLM models and parameters.
Questions:
- How does the integration of advanced GPU technology impact the efficiency and performance of AI tasks compared to traditional CPU processing?
- What are the potential benefits and challenges of using different LLM models with varying parameters, such as the trade-off between model size and response quality?
- Considering the resource-intensive nature of high-parameter LLM models, how can businesses justify the cost and resource allocation for utilizing these models in practical applications?
- 计算能力不足,即使用模型也需要更高的开发和维护成本。
- 开源模型的实现和验证也存在一定差异。
- 如果一个模型无法完成《水浒传》这个书,那么0.5b这种胡说八道类似的模型,商业价值是啥?有啥商业价值?
- 需要13b 或更高的计算能力才能回答问题质量高很多(RAG简单一下就有明显效果)。
- 探索:OpenAI ChatGPT3.5 ChatGPT4的不同价格和回答质量,因为开发成本和计算能力不同。
- 全量 fp16 int4 这些参数在测试中没有考虑它们的影响,可能会对模型的性能产生重要影响。




最新文章
折腾了一上午,终于升级成功了。
看Twitter,我需...
周六下午,很充实的4个小时,一群小伙伴在热烈讨论SEO...
- 零钥匙出门
- 家装DIY小米智能家居
- 乒乓球
- 皮作
2025年秋,西安业已秋雨连绵38天多, 于是乎,在秋...
热门文章
2024年 甲辰龙年春节假期,我看了2本小说,茅盾文学...
2023年,三年疫情过后第一个春天,我开始了骑行: 空...
算力为王时代: CPU --> GPU
GPU这...在VR应用中,有一个相对简单的虚拟现实体验,那...
相关【AI学习笔记】文章
查看所有相关【AI学习笔记】文章{kind=link}
折腾了一上午,终于升级成功了。
看Twitter,我需求是2个功能: SuperGrok和长文章 。
这两个功能...
{kind=link}
2025年秋,西安业已秋雨连绵38天多, 于是乎,在秋雨绵绵中,捡起来ComfyUI,步步为营、稳打稳拿:
- B站...
{kind=link}
算力为王时代: CPU --> GPU
GPU这几年,真的是火爆很: 机器学习、挖矿、人工智能